Are Internet Explorer's days numbered?
Web designers and developers are often heard to pour vitriol in the direction of Internet Explorer. I personally find myself cursing its name perhaps once a week. It's always difficult to believe this is a product Microsoft is still trying to promote.
Contemporary GUI development toolkits require an HTML rendering component: Java has javax.swing.JEditorPane; KDE has KHTML; Gtk has GtkHTML. MFC and .NET have Internet Explorer. In this task it is arguably successful: despite being too heavyweight, buggy, and non-portable, it is at least fast and very simple to embed. The applications which use Internet Explorer tend to use it in restricted circumstances so that the largest class of failings - how it measures up to the wild wild web - are not encountered.
With Firefox 3 right around the corner and a total radio silence on a potential IE8, it's worth considering how much Microsoft has to do to maintain its web browser's competitiveness.
Standards
Internet Explorer is of course lacking in standards support. XHTML and SVG are hugely significant formats entirely unsupported by Internet Explorer. That Internet Explorer supports RSS now is immaterial while nobody knows exactly what RSS is for, but at least it's not a misfeature. New standards are coming thick and fast, faster than Microsoft has been implementing them. The formats Internet Explorer does supports are not fully or correctly integrated with one another and as the collection of web formats continues to flourish this integration problem becomes harder and harder.
For example, Internet Explorer boasts a near-perfect XSL implementation. However, it dumps and reparses the result document. Because it doesn't support XHTML anyway, the resulting tree is interpreted as tagsoup. All of this decouples XML processing from the final DOM and introduces an array of bugs.
It would be hard for a non-programmer to imagine how much functionality this kind of integration entails. It's relatively easy to write or licence code which implements individual standards but integrating all of them to form one coherent whole - as is invariably implied in the specifications themselves - is much more work. The following diagram is admittedly somewhat arbitrary in scope, but may illustrate my point:
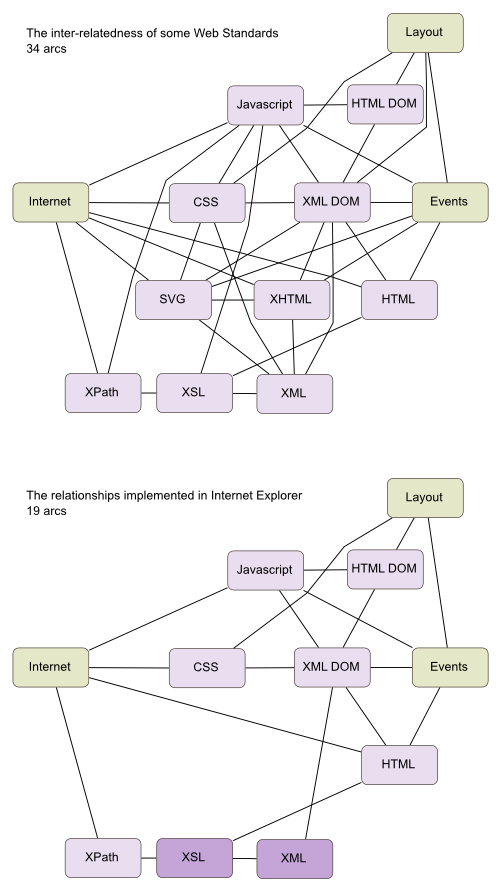
Bugs
What Internet Explorer does implement is riddled with bugs. These bugs are easy to fix but there are a huge number of them. Whereas the Mozilla project employs Bugzilla to allow users to report bugs, Internet Explorer relies on a testing team, and this is bound to result in fewer bugs being spotted. CSS is most often cited as an example because the bugs here result in immediately visual results, such the striking failure of Internet Explorer to render the Acid2 test, stemming not only from missing features but the incorrect implementations of many.
However, there are similar bugs throughout the software, documented in various sources around the Internet, alas none comprehensive enough to be a first port-of-call. My assertion here is that Microsoft has made some improvement between IE6 and IE7, they are unlikely even to be aware of all of the bugs that their software exhibits.
Misfeatures
In many cases Microsoft has deliberately violated the specifications. This is worse than simple omission: Microsoft has started down some paths from which it would be hard to return to a position of standards compliance. Even if they can appreciate that these features are unnecessary and undesirable, they will be disinclined to remove features which they have previously promoted which can cause existing applications and websites to break. This actually makes Microsoft's work harder, because they have to implement more than just standards compliance; they have to support their own misfeatures too, which are certainly not guaranteed to work interoperable with accepted web standards.
Examples include Moniker, which is an unsolicited part of the Microsoft netcode which guesses resource MIME types rather than obeying the HTTP Content-Type header, and conditional comments, under which CSS and HTML comments are not ignored, but interpreted, and certain statements force Internet Explorer to omit sections of markup.
Embedding
A disproportionate amount of Microsoft's development budget for Internet Explorer has to be spent on continued support of ActiveX. ActiveX connects the browser to arbitrary code. This is useful for the GUI toolkit aspect of Internet Explorer but it is detrimental for websites - not only because it is a source of security vulnerability, but because it is not portable so alternatives have to be found. ActiveX is not in very significant use in the wild, except as a route to browser compromise of course. This is both because of Microsoft's own security restrictions (which have neutered it) and other browsers' refusal to support it (which means it's not portable anyway). Meanwhile Javascript has become much more portable and powerful, such that ActiveX is no longer necessary for most rich web applications.
Developers, Developers, Developers
Web developers want standalone and even cross-platform versions of Internet Explorer. This is getting less likely: Microsoft is aiming to make new software compatible only with Windows Vista. Microsoft may be entitled not to want to play catch up in this area, but the approach could start to alienate them from web developers (a demographic skewed towards Linux), designers (whose demographic is skewed towards Mac), and everyone else (skewed towards Windows XP... for the moment).
The internal inconsistencies in Internet Explorer also rule out an extension for developers as good as Firebug, for the foreseeable future. There is an Internet Explorer developer toolbar which looks similar but which is vastly inferior and only serves to highlight Internet Explorer's bugginess.
Failing to cater to developers doesn't overcome the requirement for developers to target Internet Explorer... yet. But it has an effect. Personally, I have converted more than 25 people to Firefox.
Conclusions
Until we can gauge the rate of progress being made towards Internet Explorer 8, it's hard to assess if Microsoft is taking their web browser seriously. Five years of neglect leaves a lot of ground to make up, as described above. But I'd go so far as to predict that Microsoft won't keep up with the competition. They don't have the inclination, and although they have the money it's impossible to instantly convert money into good software (especially when you've got no experience at doing so... ;-). Internet Explorer 7 is really not all that different to Internet Explorer 6.
If the gulf does continue to widen, some sites - at first intranet sites, and sites developed by Firefoxies and non-Windows users - may drop Internet Explorer support to focus on real browsers. At that moment, Internet Explorer's days as a desktop web browser really will be numbered.
